


Thanks!
Thursday, March 29, 2007
We just wanted to thank all the attendees/presenters/volunteers/sponsors again for making ICWSM a great conference.We will slowly be filling up the blog and website with pictures, presentations and video (where available) so please keep an eye out on the blog.
For those that missed it, the best paper award went to "TagAssist: Automatic Tag Suggestion for Blog Posts," by Sanjay Sood, Sara Owsley, Kristian Hammond and Larry Birnbaum
See you all next year in Seattle.
posted by ICWSM at 5:31 PM
--
2 comments
![]()
Event Detection and Visualization for Social Text Streams
Wednesday, March 28, 2007
Qiankun Zhao and Prasenjit MitraIn this paper, we propose to detect events from social text streams by exploring the content as well as the temporal, and social dimensions. We define the term event in the social text streams(e.g., blogs, emails, and Usenets) as a set of relations between social actors on a specific topic over a certain time period. We represent social text streams as multi-graphs, where each node represents a social actor and each edge represents a piece of text communication that connects two actors. The content and temporal associations within each text piece are embedded in the corresponding edge. Then, events are detected by combining text-based clustering, temporal segmentation, and graph cuts of social networks. Moreover, we provide a multi-dimensional visualization tool that visualizes the relations between different events along the three different dimensions. Experiments conducted with the Enron email dataset1 show the advantages of exploring the social and temporal dimensions along with content, and the usefulness of the visualization tool.
Short Paper
posted by ICWSM at 10:23 AM
--
0 comments
![]()
Intertemporal Topic Correlations in Online Media: A Comparative Study on Weblogs and News Websites
Jean-Philippe Cointet, Emmanuel Faure and Camille RothWe address the issue of intertemporal topic correlations in a selection of online media consisting of political weblogs and press website content. We wish to investigate in which way various information sources may be correlated, therefore preceding and maybe influencing each other. We use hidden Markov modeling to exhibit dynamic relationships in topic occurrences between distinct groups of weblogs; thereby considering topic distributions over weblog groups as system states, looking for minimal causal states, and exhibiting their transition probabilities. Beyond behavioral correlations between some groups of blogs and online media, we also identify varied and richer types of inter-group patterns. In particular, using a very compact description, we could infer interpretations as to how diverse groups of blogs behave with respect to each other as regards raising and discussing issues.
Short Paper
posted by ICWSM at 10:21 AM
--
0 comments
![]()
Feeds That Matter: A Study of Bloglines Subscriptions
Akshay Java, Pranam Kolari, Tim Finin, Anupam Joshi and Tim OatesAs the Blogosphere continues to grow, finding good quality feeds is becoming increasingly difficult. In this paper we present an analysis of the feeds subscribed by a set of publicly listed Bloglines users. Using the subscription information, we describe techniques to induce an intuitive set of topics for feeds and blogs. These topic categories, and their associated feeds, are key to a number of blog-related applications, including the compilation of a list of feeds that matter for a given topic. The site FTM! (Feeds That Matter) was implemented to help users browse and subscribe to an automatically generated catalog of popular feeds for different topics.
Full Paper
posted by ICWSM at 10:20 AM
--
2 comments
![]()
Using Tags and Clustering to Identify Topic-Relevant Blogs
Conor Hayes and Paolo AvesaniThe Web has experienced an exponential growth in the use of weblogs or blogs. Blog entries are generally organised using tags, informally defined labels which are increasingly being proposed as a 'grassroots’ answer to SemanticWeb standards. Despite this, tags have been shown to be weak at partitioning blog data. In this paper, we demonstrate how tags provide useful, discriminating information where the blog corpus is initially partitioned using a conventional clustering technique. Using extensive empirical evaluation we demonstrate how tag cloud information within each cluster allows us to identify the most topic-relevant blogs in the cluster. We conclude that tags have a key auxiliary role in refining and confirming the information produced using typical knowledge discovery techniques.
Full Paper
posted by ICWSM at 8:55 AM
--
2 comments
![]()
Using Ontologies to Strengthen Folksonomies and Enrich Information Retrieval in Weblogs: Theoretical background and corporate use-case
Alexandre PassantWhile free-tagging classification is widely used in social software implementations and especially in weblogs, it raises various issues regarding information retrieval. In this paper, we describe an approach that mixes folksonomies and semantic web technologies in order to solve some of these problems, and to enrich information retrieval capabilities among blog posts.
We first introduce the corporate context of the study and the issues we have faced that motivated our approach. Then, we argue how the use of domain ontologies combined with the SIOC vocabulary on the top of an existing folksonomy and weblogging platform offers a way to get rid of free-tagging classification flaws, and enhances information retrieval by suggesting related blog posts.
Aside of the theoretical background, this paper also focuses on implementation. We present experimental results of this approach through the example of add-ons to a corporate blogging platform and the associated semantic web search engine, that extensively uses RDF and other semantic web technologies to find appropriate information and suggest related posts.
Full Paper
posted by ICWSM at 8:54 AM
--
0 comments
![]()
Tags are not metadata, but "just more content" - to some people
Bettina Berendt and Christoph HanserThe authoring of tags -- unlike the authoring of traditional metadata -- is highly popular among users. This harbours unprecedented opportunities for organizing content. However, tags are still poorly understood. What do they "mean", in what senses are they similar to or different from metadata? Different tags support different communities, but how exactly do they reflect the plurality of opinions,what is the relation to individual differences in authoring and reading? In this paper, we offer a definition and empirical evidence for the claim that "tags are not metadata, but just more content". The analysis rests on a multi-annotator classification of a blog corpus using the WordNet domain labels system (WND), the development of a system of text-classification methods using WordNet and WND, and a quantitative and qualitative comparative analysis of these classifications. We argue that the notion of a "gold standard" may be meaningless in social media, and we outline possible consequences for labelling and search-engine development.
Full Paper
posted by ICWSM at 7:42 AM
--
2 comments
![]()
TagAssist: Automatic Tag Suggestion for Blog Posts
Sanjay Sood, Sara Owsley, Kristian Hammond and Larry BirnbaumIn this paper, we describe a system called TagAssist that provides tag suggestions for new blog posts by utilizing existing tagged posts. The system is able to increase the quality of suggested tags by performing lossless compression over existing tag data. In addition, the system employs a set of metrics to evaluate the quality of a potential tag suggestion.
Coupled with the ability for users to manually add tags, TagAssist can ease the burden of tagging and increase the utility of retrieval and browsing systems built on top of tagging data.
Full Paper
posted by ICWSM at 7:41 AM
--
1 comments
![]()
An Activity-based Perspective of Collaborative Tagging
Shreeharsh Kelkar, Ajita John and Doree SeligmannCollaborative tagging offers an interesting framework for studying online activity as users, topics (tags), and resources (bookmarks) get associated with each other through a folksonomy. In this paper, we consider an activity-based perspective of collaborative tagging where activity is defined as the act of associating a tag with a bookmark by a user. The perspective categorizes activities based on two defined measures: intensity and spread, which indicate the level and range, respectively, of the tagging activity, measured for both users and tags. Our block-model perspective juxtaposes two subperspectives: (i) A user perspective that captures the activity of users across different tags and, (ii) A tag perspective that captures the activity in tags across different users. This juxtaposition can provide an insight into different communities of users and tags. It has applications in identifying trends and types of interests in web communities as well as expertise, staffing needs and knowledge gaps in enterprise communities. Results obtained by analyzing data from a commercial tagging service offer interesting case studies.
Full Paper
posted by ICWSM at 7:38 AM
--
0 comments
![]()
Expressing Social Relationships on the Blog through Links and Comments
Tuesday, March 27, 2007
| Noor Ali-Hasan and Lada Adamic Blogs, regularly updated online journals, allow people to quickly and easily create and share online content. Most bloggers write about their everyday lives and generally have a small audience of regular readers. Readers interact with bloggers by contributing comments in response to specific blog posts. Moreover, readers of blogs are often bloggers themselves and acknowledge their favorite blogs by adding them to their blogrolls or linking to them in their posts. This paper presents a study of bloggers. online and real life relationships in three blog communities: Kuwait Blogs, Dallas/Fort Worth Blogs, and United Arab Emirates Blogs. Through a comparative analysis of the social network structures created by blogrolls and blog comments, we find different characteristics for different kinds of links. Our online survey of the three communities reveals that few of the blogging interactions reflect close offline relationships, and moreover that many online relationships were formed through blogging. Full Paper |  |
posted by ICWSM at 3:03 PM
--
5 comments
![]()
Finding Patterns in Blog Shapes and Blog Evolution
 | Mary McGlohon, Jure Leskovec, Christos Faloutsos, Matthew Hurst and Natalie Glance Can we cluster blogs into types by considering their typical posting and linking behavior? How do blogs evolve over time? In this work we answer these questions, by providing several sets of blog and post features that can help distinguish between blogs. The first two sets of features focus on the topology of the cascades that the blogs are involved in, and the last set of features focuses on the temporal evolution, using chaotic and fractal ideas. We also propose to use PCA to reduce dimensionality, so that we can visualize the resulting clouds of points. We run all our proposed tools on the icwsm dataset. Our findings are that (a) topology features can help us distinguish blogs, like 'humor' versus 'conservative' blogs (b) the temporal activity of blogs is very non-uniform and bursty but (c) surprisingly often, it is self-similar and thus can be compactly characterized by the so-called bias factor (the '80’ in a recursive 80-20 distribution). Full Paper |
posted by ICWSM at 3:02 PM
--
0 comments
![]()
On the Structure, Properties and Utility of Internal Corporate Blogs
| Pranam Kolari, Tim Finin, Kelly Lyons, Yelena Yesha, Yaacov Yesha, Stephen Perelgut and Jen Hawkins Weblogs, or blogs are radically changing the face of communication within enterprises. While at the minimum blogs empower employees to publicly voice opinion and share expertise, collectively they improve collaboration and enable internal business intelligence. Though the power of blogs within organizations is well accepted, their properties, structure and utility has not yet been formally analyzed. In this paper, we study the use of blogs within a large corporation to reveal some of the interesting characteristics. We propose new techniques to model the reach and impact of posts using the corporate hierarchy. We discuss how such a technique can feed into tools that identify the reach of blog posts, and the emergence of trends and experts within an organization. Full Paper | 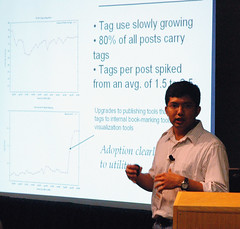 |
posted by ICWSM at 3:01 PM
--
2 comments
![]()
How to Overcome Tiredness: Estimating Topic-Mood Associations
 | Krisztian Balog and Maarten de Rijke We address the task of associating moods with a given topic, using a large set of mood-annotated blog posts. We argue that a simple frequency-based baseline does not suffice as it fails to capture topic-dependence. Instead, we propose three models based on language modeling techniques to accomplish the topic-mood association task. Based on anecdotal evidence and other considerations, including complexity and efficiency, we identify a clearly preferred model. Short Paper |
posted by ICWSM at 1:10 PM
--
0 comments
![]()
Personality Impressions Based on Facebook Profiles
Samuel D. Gosling, Sam Gaddis and Simine VazireAlthough still largely the province of teenagers and college students, Online Social-Networking Websites (OSNWs) like MySpace and Facebook are increasingly used by people in the 24- 54 year age range and many employers now use them to check out prospective employees. For many people, these websites have changed the dynamics of how individuals become acquainted. Indeed, viewing an individual’s profile on MySpace or Facebook now features early in the process of getting to know others, often serving as the very first exposure. But how accurate are the impressions based on OSNW profiles? Our previous research on personal websites suggests OSNW profiles should provide more information about targets than most other sources, including actually meeting the person. Here we examine impressions based on 133 Facebook profiles, comparing them with how the targets see themselves and are seen by close acquaintances. As in our previous research, results show generally strong patterns of convergence, although the accuracy correlations vary considerably across traits. Findings are discussed with regard to the increasing role of technology-borne social information in everyday interpersonal interactions
Short Paper

posted by ICWSM at 1:09 PM
--
0 comments
![]()
On Estimating The Geographic Distribution of Social Media
Matthew Hurst, Matthew Siegler and Natalie GlanceMany social media platforms allow the user to provide profile information. This information is generally presented in a semi-structured manner either on a profile page or on the weblog home page itself. This paper describes a novel wrapper induction method that extracts profile data. Our ultimate goal is to estimate the geographic distribution of weblog authors and to that end we provide an analysis of the location information discovered for each author in a large database of weblog posts.
Full Paper

posted by ICWSM at 1:08 PM
--
1 comments
![]()
Identifying more bloggers: Towards large scale personality classification of personal weblogs
Scott Nowson and Jon OberlanderWe report new results on the relatively novel task of automatic classification of blog author personality. Promisingly high classification accuracies have recently been reported for four important personality traits (Extraversion, Neuroticism, Agreeableness and Conscientiousness). But the blog corpus used in that work required careful preparation, and was consequently quite small (with less than a hundred authors; and less than half a million words). Here, we provide an initial report on the classification accuracies that can be achieved when classifiers conditioned on the small corpus are applied to a larger, automatically-acquired blog corpus, using lower granularity personality data and substantially less manual preparation (with over a thousand bloggers, and approximately five million words). Predictably, results on the larger corpus are not as impressive as those on the smaller; nevertheless, they point the way forward for further work.
Full Paper

posted by ICWSM at 1:07 PM
--
0 comments
![]()
Of Men, Women, and Computers: Data-Driven Gender Modeling for Improved User Interfaces
Hugo Liu and Rada MihalceaMen and women have unique sensibilities for information, which can be tapped to create gender-sensitive user interfaces that appeal more specifically to each sex. Building on previous research in gender psychology and also in user modeling, we take a data-driven approach to understanding gender preferences by mining a large corpus of 150,000 weblog entries--half authored by men, half by women. This paper reports two kinds of contributions. First, we employ automatic language processing, semantic analysis, and reflexive ethnography to articulate gender preferences for several dimensions of gender space will provide valuable insight to user interface designers-- time, color, size, socialness, affect, and cravings. Second, we employ statistical gender models to build GENDERLENS--a novel intelligent news filtering system that customizes news based on the gender of its reader. A user evaluation found that GENDERLENS successfully predicted men and women’s preferences for news, with statistical significance for four out of five news genres tested.
Full Paper

posted by ICWSM at 1:04 PM
--
1 comments
![]()
Identifying Facets in Query-Biased Sets of Blog Posts
Wouter de Winter and Maarten de RijkeWe investigate the identification of facets of query-biased sets of blog posts. Given a set of blog posts relevant to a topic, we compare several methods for identifying facets of the topic in this set. Building on a clustering of a set of blog posts, we compare several cluster labeling methods, and find that a method that makes use of blog and blog search specific features outperforms other methods. We also present efficiencyimproving feature sets for clustering; our proposed method is fast enough to be deployed online.
Short Paper

posted by ICWSM at 11:10 AM
--
0 comments
![]()
Using Blog Properties to Improve Retrieval
Gilad MishneThis paper describes three simple heuristics which improve opinion retrieval effectiveness by using blog-specific properties. Blog timestamps are used to increase the retrieval scores of blog posts published near the time of a significant event related to a query; an inexpensive approach to comment amount estimation is used to identify the level of opinion expressed in a post; and query-specific weights are used to change the importance of spam filtering for different types of queries. Overall, these methods, combined with non-blog-specific retrieval approaches, result in substantial improvements over state-of-the-art.
Short Paper

posted by ICWSM at 10:47 AM
--
0 comments
![]()
Visual Analysis of Weblog Content
Michelle L. Gregory, Deborah Payne, David McColgin, Nicolas Cramer and Douglas LoveIn recent years, one of the advances of the World Wide Web is social media and one of the fastest growing aspects of social media is the blogosphere. Blogs make content creation easy and are highly accessible through web pages and syndication. With their growing influence, a need has arisen to be able to monitor the opinions and insight revealed within their content. In this paper we describe a technical approach for analyzing the content of blog data using a visual analytic tool, IN-SPIRE, developed by Pacific Northwest National Laboratory. We highlight the capabilities of this tool that are particularly useful for information gathering from blog data.
Short Paper

posted by ICWSM at 10:30 AM
--
0 comments
![]()
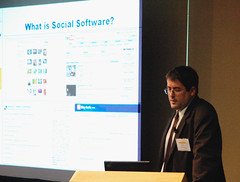
Watching the Blogosphere: Knowledge Sharing in the Web 2.0
Ralf Klamma, Yiwei Cao and Marc SpaniolWeblogs are new media forming the blogosphere. Blogs feature the emerging Web 2.0 technologies and social software. In this paper we discuss the use of blogs for knowledge management by identifying relevant knowledge work processes performed by bloggers. With a media theoretic framework we have analyzed functionalities of blog software and made a comparison of wellknown blog and community providers. Finally, we present the models needed to do cross-media community specific analysis of blog data for blogwatching software. This software enables the analysis and the prediction of knowledge sharing and spreading processes in the Web 2.0.
Full Paper
posted by ICWSM at 10:25 AM
--
0 comments
![]()
Modeling Trust and Influence in the Blogosphere Using Link Polarity
Anubhav Kale, Amit Karandikar, Pranam Kolari, Akshay Java, Tim Finin and Anupam JoshiThere is a growing interest in social network analysis to explore how communities and individuals spread influence. We describe techniques to find "like minded" blogs based on blog-to-blog link sentiment for a particular domain. Using simple sentiment detection techniques, we identify the polarity (positive, negative or neutral) of the text surrounding links that point from one blog post to another. We use trust propagation models to spread this sentiment from a subset of connected blogs to other blogs and deduce like-minded blogs in the blog graph. Our techniques demonstrate the potential of using polar links for more generic problems such as detecting trustworthy nodes in web graphs.
Short Paper

posted by ICWSM at 8:43 AM
--
0 comments
![]()
Large-Scale Sentiment Analysis for News and Blogs
Namrata Godbole, Manja Srinivasaiah and Steven SkienaNewspapers and blogs express opinion of news entities (people, places, things) while reporting on recent events. We present a system that assigns scores indicating positive or negative opinion to each distinct entity in the text corpus. Our system consists of a sentiment identification phase, which associates expressed opinions with each relevant entity, and a sentiment aggregation and scoring phase, which scores each entity relative to others in the same class. Finally, we evaluate the significance of our scoring techniques over large corpus of news and blogs.
Short Paper

posted by ICWSM at 8:42 AM
--
0 comments
![]()
Fusion Approach to Finding Opinions in Blogosphere
Kiduk Yang, Ning Yu, Alejandro Valerio, Hui Zhang and Weimao KeIn this paper, we describe a fusion approach to finding opinion about a given target in blog postings. We tackled the opinion blog retrieval task by breaking it down to two sequential subtasks: ontopic retrieval followed by opinion classification. Our opinion retrieval approach was to first apply traditional IR methods to retrieve on-topic blogs, and then boost the ranks of opinionated blogs using combined opinion scores generated by four opinion assessment methods. Our opinion module consists of Opinion Term Module, which identify opinions based on the frequency of opinion terms (i.e., terms that only occur frequently in opinion blogs), Rare Term Module, which uses uncommon/rare terms (e.g., "sooo good") for opinion classification, IU Module, which uses IU (I and you) collocations, and Adjective-Verb Module, which uses computational linguistics’ distribution similarity approach to learn the subjective language from training data.
Full Paper

posted by ICWSM at 8:37 AM
--
3 comments
![]()
Discovering Weblog Communities: A Content- and Topology-Based Approach
Monday, March 26, 2007
Jeroen Bulters and Maarten de RijkeWeblogs have become a leading form of self-publication on the web. Personal weblogs are often considered to represent a person, and the links between webogs can naturally be given a social interaction. Against this background, finding a community around a given weblog--i.e., identifying a set of weblogs that forms a natural group together with the starting point, because of content or social reasons--is a very natural task. Traditional methods for community finding methods focus almost exclusively on topology analysis. In this paper we present a novel method for discovering weblog communities that incorporates both topology analysis and content analysis. We evaluate our method in a small-scale user study, analyze the contributions of the various components of our approach, and compare it against a state-of-the-art topologybased community finding algorithm.
Short Paper

posted by ICWSM at 3:42 PM
--
2 comments
![]()
Structural Link Analysis from User Profiles and Friends Networks: A Feature Construction Approach
William Hsu, Joseph Lancaster, Martin Paradesi and Tim WeningerWe consider the problems of predicting, classifying, and annotating friends relations in friends networks, based upon network structure and user profile data. First, we document a data model for the blog service LiveJournal, and define a set of machine learning problems such as predicting existing links and estimating inter-pair distance. Next, we explain how the problem of classifying a user pair in a social network, as directly connected or not, poses the problem of selecting and constructing relevant features. We document feature analyzers for attributes that depend only on graph attributes, those that depend on individual user demographics and set-valued attributes (e.g., interests, communities, and educational institutions), and those that depend on candidate user pairs. We then extend our data model using whole-network attributes and report machine learning experiments on learning the concept of a connected pair of friends from LiveJournal data. Finally, we develop a theory of dependent types for deriving causal explanations and discuss how this can be used to scale statistical relational learning up to our full corpus, a recent crawl of over a million records from LiveJournal.
Full Paper

posted by ICWSM at 3:41 PM
--
0 comments
![]()
Looking at the Blogosphere Topology through Different Lenses
Xiaolin Shi, Belle Tseng and Lada AdamicThe blogosphere is a vast and dynamic complex network. Any examination of the structure of such a network is dependent on the selection of blogs sampled and the time frame of the sample. By comparing two large blog datasets, we demonstrate that samples may differ significantly in their coverage but still show consistency in their aggregate network properties. We further compare the structure of a blog dataset with and without spam blogs, which account for a majority of the links in one sample. We also show that properties such as degree distributions and clustering coeffcients depend on the time frame over which the network is aggregated.
Full Paper

posted by ICWSM at 3:40 PM
--
0 comments
![]()
Traffic Characteristics and Communication Patterns in Blogosphere
Fernando Duarte, Bernardo Mattos, Azer Bestavros, Virgilio Almeida and Jussara AlmeidaWe present a thorough characterization of the access patterns in blogspace -- a fast-growing constituent of the content available through the Internet -- which comprises a rich interconnected web of blog postings and comments by an increasingly prominent user community that collectively define what has become known as the blogosphere. Our characterization of over 35 million read, write, and administrative requests spanning a 28-day period is done from three different blogosphere perspectives. The server view characterizes the aggregate access patterns of all users to all blogs; the user view characterizes how individual users interact with blogosphere objects (blogs); the object view characterizes how individual blogs are accessed. Our findings support two important conclusions. First, we show that the nature of interactions between users and objects is fundamentally different in blogspace than that observed in traditional web content. Access to objects in blogspace could be conceived as part of an interaction between an author and its readership. As we show in our work, such interactions range from one-to-many "broadcast-type" and many-to-one "registration-type" communication between an author and its readers, to multi-way, iterative "parlor- type" dialogues among members of an interest group. This more-interactive nature of the blogosphere leads to interesting traffic and communication patterns, which are different from those observed in traditional web content. Second, we identify and characterize novel features of the blogosphere work- load, and we investigate the similarities and differences between typical web server and blogosphere server workloads.
Full Paper

posted by ICWSM at 3:39 PM
--
4 comments
![]()
The Boardscape: Creating a Super Social Network of Message Boards
John Breslin, Ron Kass and Uldis BojarsA Web-based message board or forum is an online area where discussions are held by many Internet users on a variety of subjects. More recently, online social networks have been created for various purposes: job searching, dating, band promotion, etc. Many social networking sites have also incorporated community discussion features such as message boards. Rather than add a message board to a social network, this paper proposes to take advantage of the large number of message boards and implicit virtual communities that are already available to automatically create a "super" social network. The Boardscape is this network: an interconnected set of bulletin board users, message boards and topic threads with semantic definitions linking the various pieces together. We will discuss our approaches to realize the vision of the Boardscape, including Klostu and the SIOC project.
Short Paper

posted by ICWSM at 2:07 PM
--
0 comments
![]()
Social Browsing on Flickr
Kristina Lerman and Laurie JonesThe new social media sites--blogs, wikis, del.icio.us and Flickr, among others--underscore the transformation of the Web to a participatory medium in which users are actively creating, evaluating and distributing information. The photo-sharing site Flickr, for example, allows users to upload photographs, view photos created by others, comment on those photos, etc. As is common to other social media sites, Flickr allows users to designate others as "contacts" and to track their activities in real time. The contacts (or friends) lists form the social network backbone of social media sites. These social networks facilitate new ways of interacting with information, e.g., through what we call social browsing. The contacts interface on Flickr enables users to see latest images submitted by their friends. Through an extensive analysis of Flickr data, we show that social browsing through the contacts’ photo streams is one of the primary methods by which users find new images on Flickr. This finding has implications for creating personalized recommendation systems based on the user’s declared contacts lists.
Short Paper

posted by ICWSM at 2:06 PM
--
0 comments
![]()
On the Evolution of Wikipedia
Rodrigo Almeida, Barzan Mozafari and Junghoo ChoA recent phenomenon on the Web is the emergence and proliferation of new social media systems allowing social interaction between people. One of the most popular of these systems is Wikipedia that allows users to create content in a collaborative way. Despite its current popularity, not much is known about how users interact with Wikipedia and how it has evolved over time.
In this paper we aim to provide a first, extensive study of the user behavior on Wikipedia and its evolution. Compared to prior studies, our work differs in several ways. First, previous studies on the analysis of the user workloads (for systems such as peer-to-peer systems [10] and Web servers [2]) have mainly focused on understanding the users who are accessing information. In contrast, Wikipedia’s provides us with the opportunity to understand how users create and maintain information since it provides the complete evolution history of its content. Second, the main focus of prior studies is evaluating the implication of the user workloads on the system performance, while our study is trying to understand the evolution of the data corpus and the user behavior themselves.
Our main findings include that (1) the evolution and updates of Wikipedia is governed by a self-similar process, not by the Poisson process that has been observed for the general Web [4, 6] and (2) the exponential growth of Wikipedia is mainly driven by its rapidly increasing user base, indicating the importance of its open editorial policy for its current success. We also find that (3) the number of updates made to the Wikipedia articles exhibit a power-law distribution, but the distribution is less skewed than those obtained from other studies.
Full Paper

posted by ICWSM at 1:59 PM
--
0 comments
![]()
Personal Network Aggregation System for Real-time Communication Support
Toshiyuki Hirata, Ikki Ohmukai, Hideaki Takeda and Susumu KunifujiIn this paper we propose a system that aggregates together user’s multiple personal networks, constructs a personal network that unifies their data and as well as adding activity information for each user inside the unified personal network. The system also allows transmission of user data within one’s own personal network using P2P. This makes unification of use of multiple personal networks possible. Furthermore, this also allows other user’s information to be fully understood, greatly helping the process of communication.
Short Paper
posted by ICWSM at 10:03 AM
--
2 comments
![]()
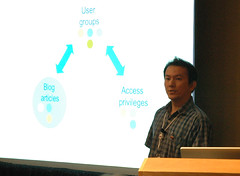
A Usability Study of an Access Control System for Group Blogs
Indratmo and Julita VassilevaBlogs are a medium to express thoughts, feelings, and opinions. Once published, blog articles potentially become persistent and can be read by non-intended audiences, causing hurt feelings and other troubles. In part these problems are due to the lack of access control in blogs. We propose an access control framework for group blogs. Compared to the typical access control in blogging tools, our system differs in a few aspects. First, the system enables bloggers to grant different access privileges to different audiences over a single blog article. That is, it associates access privileges to people rather than to artifacts (e.g., articles, blogs). Second, the system allows a blogger to create a collaborative space with other bloggers, for example by allowing others to edit his or her articles. Third, the management of access control is integrated with the process of writing and editing blog articles, facilitating the main workflow of the user. We conducted a usability study to evaluate our system and get constructive feedback from users. In this article, we present the proposed access control system, the results of the study, and analysis of the results.
Short Paper
posted by ICWSM at 10:02 AM
--
0 comments
![]()
Groups and Group-Instantiations in Mobile Communities - Detection, Modeling and Applicationsnd Applications
Georg GrohThe paper investigates techniques for the detection and modeling of groups of people in a mobile community also interacting in the real world. In this scenario, the concept of contextual manifestations or instantiations of existing social groups is of special significance. In view of detecting and modeling of groups and their instantiations, several examples for classes of data (location- and velocity-data, natural language interest phrases and text-based communication-data) in the information spaces of mobile communities are investigated. Similarity measures between people are constructed and verified by empiric means or through stochastic simulation. On this basis, special clustering approaches for the detection and modeling of groups are developed and tested. The paper concludes with a discussion on possible applications for the methods which have been developed.
Full Paper

posted by ICWSM at 10:00 AM
--
0 comments
![]()
Building Trust with Corporate Blogs
Paul DwyerThe personal relationships that companies once had with customers degenerated into the cold automaticity of datagathering with the widespread adoption of management information systems. By restoring a human face to a company’s self-presentation, blogging has been heralded as a paradigm shift in the way companies interact with customers. This study tests a model relating the content of an author's blog posts to readers' responses. It suggests that companies can use blogging to complement customer relationship management processes to the extent their customers exhibit an organic desire to commune by combining provocative informational content with expressions of benevolent intent. Such consumers respond well to these overtures, showing evidence of increased subject-matter involvement, liking and trust. The study also proposes a way to measure diversity of thought in reader comments to guard against being unduly swayed by a vocal minority.
Full Paper
posted by ICWSM at 9:58 AM
--
1 comments
![]()
Paper sessions
We're going to try to post one new post per paper. Feel free to ask extra questions in the comments and hopefully the authors will answer... :)
posted by ICWSM at 9:29 AM
--
0 comments
![]()
All Blogs Are Not Made Equal: Exploring Genre Differences in Sentiment Tagging of Blogs
Alina Andreevskaia, Sabine Bergler and Monica UrseanuOne of the essential characteristics of blogs is their subjectivity, which makes blogs a particularly interesting domain for research on automatic sentiment determination. In this paper, we explore the properties of two most common subgenres of blogs -- personal diaries and "notebooks" -- and the effects that these properties have on performance of an automatic sentiment annotation system, which we developed for binary (positive vs. negative) and ternary (positive vs. negative vs. neutral) classification of sentiment at the sentence level. We also investigate the differential effect of inclusion of negations and other valence shifters on the performance of our system on these two subgenres of blogs.
Paper
posted by ICWSM at 7:53 AM
--
0 comments
![]()
Sentiment Analysis: Adjectives and Adverbs are Better than Adjectives Alone
Farah Benamara, Carmine Cesarano, Antonio Picariello, Diego Reforgiato and VS SubrahmanianTo date, there is almost no work on the use of adverbs in sentiment analysis, nor has there been any work on the use of adverb-adjective combinations (AACs). We propose an AAC-based sentiment analysis technique that uses a linguistic analysis of adverbs of degree. We define a set of general axioms (based on a classification of adverbs of degree into five categories) that all adverb scoring techniques must satisfy. Instead of aggregating scores of both adverbs and adjectives using simple scoring functions, we propose an axiomatic treatment of AACs based on the linguistic classification of adverbs. Three specific AAC scoring methods that satisfy the axioms are presented. We describe the results of experiments on an annotated set of 200 news articles (annotated by 10 students) and compare our algorithms with some existing sentiment analysis algorithms. We show that our results lead to higher accuracy based on Pearson correlation with human subjects.
Paper

posted by ICWSM at 7:52 AM
--
1 comments
![]()
QA with Attitude: Exploiting Opinion Type Analysis for Improving Question Answering in On-line Discussions and the News
Swapna Somasundaran, Theresa Wilson, Janyce Wiebe and Veselin StoyanovIn this paper, we explore the utility of attitude types for improving question answering (QA) on both web-based discussions and news data. We present a set of attitude types developed with an eye toward QA and show that they can be reliably annotated. Using the attitude annotations, we develop automatic classifiers for recognizing two main types of attitudes: sentiment and arguing. Finally, we exploit information about the attitude types of questions and answers for improving opinion QA with promising results.
Paper
posted by ICWSM at 7:50 AM
--
0 comments
![]()